MySQL-表设计规范(二)
1. 前言
本文主要讲解
MySQL中对表的设计。例如,表的通用字段、如何选择合适的字段类型、如何处理 1:1 、1:N 的关系等等。我们设计时可以通过 PDMan 对表进行设计
2. 选择合适的字段类型
数值类型(Numeric Types):用于存储数值数据,包括整数和浮点数。例如,int、bigint、float、double、decimal 等。
字符串类型(String Types):用于存储文本和字符数据。例如,char、varchar、text、enum、set 等。
日期和时间类型(Date and Time Types):用于存储日期、时间和时间戳数据。例如,date、time、datetime、timestamp、year 等。
布尔类型(Boolean Type):用于存储布尔值,表示真或假。MySQL 中的布尔类型是 tinyint(1),可以用来存储 0 或 1。
二进制类型(Binary Types):用于存储二进制数据,如图像、音频、视频等。例如,binary、varbinary、blob 等。
2.1. 整数数据类型
整数数据类型:
tinyint、smallint、int、bigint
tinyint
- 基本定义:用于存储非常小的整数值。它占用 1 个字节的存储空间,并且可以表示范围为 -128 到 127(有符号)或 0 到 255(无符号)的整数。
- 适用场景:用于存储布尔值(0 或 1)或非常小的整数数据。
smallint
- 基本定义:用于存储较小的整数值。它占用 2 个字节的存储空间,并且可以表示范围为 -32,768 到 32,767(有符号)或 0 到 65,535(无符号)的整数。
- 适用场景:用于存储中等大小的整数数据,如年份或月份,
smallint可能是一个不错的选择
int
- 基本定义:用于存储普通大小的整数值。它占用 4 个字节的存储空间,并且可以表示范围为 -2,147,483,648 到 2,147,483,647(有符号)或 0 到 4,294,967,295(无符号)的整数。
- 适用场景:用于存储大多数整数数据。
bigint
- 基本定义:用于存储非常大的整数值。它占用 8 个字节的存储空间,并且可以表示范围为 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807(有符号)或 0 到 18,446,744,073,709,551,615(无符号)的整数。
- 适用场景:用于存储非常大的整数数据。
2.2. 浮点数数据类型
浮点数数据类型:
float、double和decimal根据数据范围、精度要求、存储空间和计算性能等因素来选择合适的浮点数数据类型
float
- 基本定义:单精度浮点数数据类型,用于存储较小范围的浮点数。它占用 4 个字节的存储空间,并提供大约 7 位数字的精度。
- 适用场景:用于存储相对较小的浮点数,并且不需要非常高的精度,例如科学计数。
double
- 基本定义:双精度浮点数数据类型,用于存储较大范围的浮点数。它占用 8 个字节的存储空间,并提供大约 15 位数字的精度。
- 适用场景:用于存储大多数浮点数,并提供相对较高的精度,例如 存储坐标就是一个不错的选择。
decimal
- 基本定义:精确的浮点数数据类型,用于存储需要高精度计算的浮点数。它占用可变的存储空间,具体取决于指定的精度和标度。精度表示总位数,标度表示小数点后的位数。
- 适用场景:decimal 可以存储非常大的数值,并提供高度精确的计算,适合于货币、金融和精确计算等领域。
2.3. 字符串数据类型
字符串数据类型:
char、varchar和text
char
- 基本定义:char 是一种固定长度的字符串类型。你需要指定一个固定的长度,范围是 0 到 255 个字符。
- 适用场景:用于长度固定的数据,例如身份证号、固定长度的标识符等
varchar
- 基本定义:可变长度的字符串类型。你需要指定一个最大长度,范围是 0 到 65,535 个字符。它只会占用实际值所需的存储空间加上额外的一些字节作为长度信息。
- 适用场景:用于长度可变的数据,例如存储用户名称、电子邮件地址等。
text
- 基本定义:用于存储大量文本数据的数据类型,其最大存储容量为约 65,535 字符。
- 适用场景:用于存储较大的文本、文章、备注等。
3. 添加通用字段
| 字段 | 类型 | 解释 | 是否必须 |
|---|---|---|---|
| id | bigint(20) | 主键 | 必须 |
| create_by | varchar(64) | 创建者 | 非必须 |
| update_by | varchar(64) | 更新者 | 非必须 |
| create_time | datetime | 更新时间 | 必须 |
| update_time | datetime | 更新时间 | 必须 |
| data_status | tinyint(1)、bit(1) | 数据状态 | 非必须 |
| remark | varchar | 记录备注 | 非必须 |
4. 一张表的字段不宜过多
张表的字段不宜过多,一般尽量不要超过20个字段。如果一张表的字段过多,表中保存的数据可能就会很大,查询效率就会很低
那如何解决字段过多问题呢?
- 如果实在需要很多字段,可以把一张大的表,拆成多张小的表,它们的主键相同即可。
- 表的字段数非常多时,可以将表分成两张表,一张作为条件查询表,一张作为详细内容表。
- 核心就是采用 1 :1 的形式将表进行拆分。
示例
假设你有一个用户信息表,其中包含用户的基本信息,如名字、密码、电子邮件地址、电话号码等。此外,还包含用户的银行卡信息,如卡号、银行名称、有效期等。
1 | # 用户的基本信息 users |
5. 设计表时,评估哪些字段需要加索引
如果有查询条件的字段,一般就需要建立索引。
唯一性太差的字段不需要创建索引,即便用于where条件.
建立联合索引时,也要考虑把重复率低而又用得多的列放在前面.
索引也不要建得太多,一般单表索引个数不要超过 5 个。因为创建过多的索引,会降低写得速度。
超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。
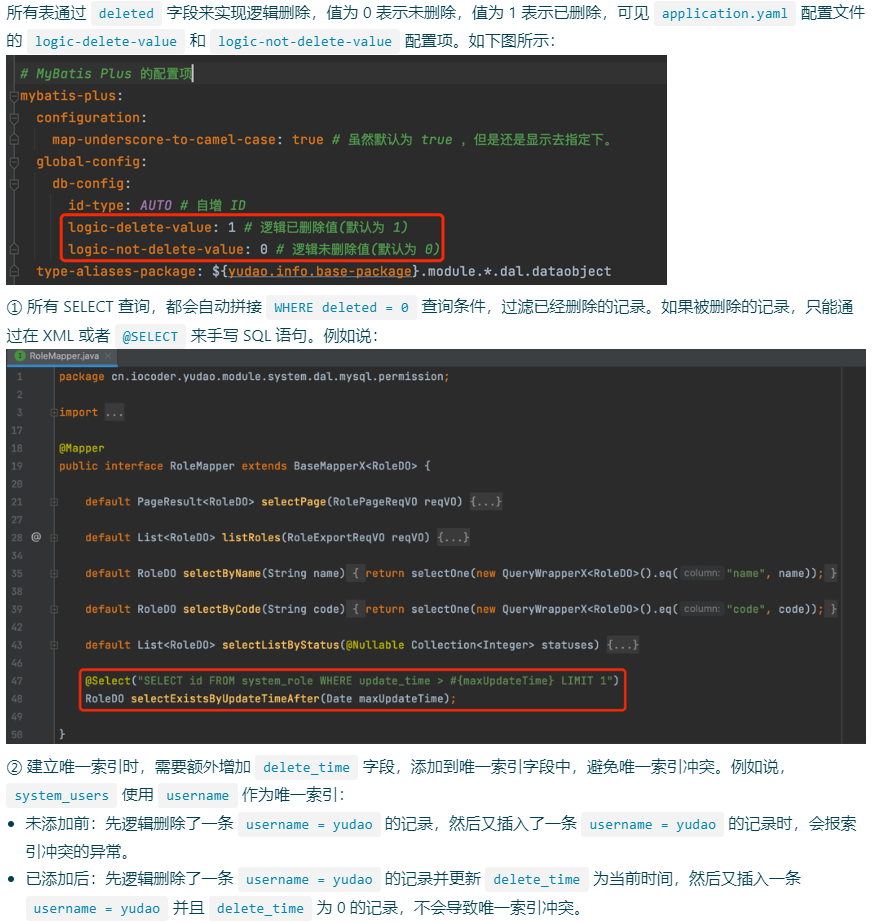
针对 逻辑删除 索引如何建立
- 逻辑删除与唯一索引:https://developer.aliyun.com/article/861184
- 唯一索引遇上逻辑删除:https://juejin.cn/post/7155492949583724551
- 保持Unique Key的逻辑删除方案:https://cloud.tencent.com/developer/article/1531915
- 如何解决逻辑删除与唯一索引冲突:https://www.lin2j.tech/archives/logic-delete-and-unique-key
- 逻辑删除和唯一索引:https://chsm.locklab.cn/2020/08/29/logical-deletion-and-unique-index/
案例
当我们查询某一条记录 , 大部分情况都会走
物理删除,我们要查询某条记录对应的SQL:where delete_flag = 0。前面我们说了 唯一性太差的字段不需要建立索引,那么 字段delete_flag这个字段只有0或者1.应该如何处理呢?
6. 不需要严格遵守 3NF
数据库三范式(3NF)基本概念
第一范式:对属性的原子性,要求属性具有原子性,不可再分解;
- 例如:学生(学号,姓名,性别,出生年月日),如果认为最后一列还可以再分成(出生年,出生月,出生日),这说明不具备原子性。
第二范式:对记录的唯一性,要求记录有唯一标识,即实体的唯一性,即不存在部分依赖;
- 例如:课程(学号、姓名、课程号、学分),学分依赖课程号,姓名依赖与学号,所以不符合二范式。
- 正确做法:学生:Student(学号, 姓名);课程:Course(课程号, 学分);选课关系:StudentCourse(学号, 课程号, 成绩)。
第三范式:对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖;
- 例如:学号, 姓名, 年龄, 学院名称, 学院电话。依赖传递: (学号) → (学生);(所在学院) → (学院电话)
- 正确做法:学生:(学号, 姓名, 年龄, 所在学院);学院:(学院, 电话)。
案例
通过业务字段冗余来减少表关联,我们设计表及其字段之间的关系, 应尽量满足第三范式。但是有时候,可以适当冗余,来提高效率
总金额 = 单价 数量,总金额这个字段的存在,表明该表的设计不满足第三范式,因为总金额可以由单价数量得到,说明总金额是冗余字段。
| 商品名称 | 商品型号 | 单价 | 数量 | 总金额 |
|---|---|---|---|---|
| 手机 | IPhone 13 Pro Max | 9000 | 5 | 45000 |
7. 数据库字段是枚举类型的,需要在comment注释清楚
如果你设计的数据库字段是枚举类型的话,就需要在comment后面注释清楚每个枚举的意思,以便于维护
正例
1 | `session_status` char(2) COLLATE utf8_bin NOT NULL COMMENT 'session授权态 00:在线-授权态有效 01:下线-授权态失效 02:下线-主动退出 03:下线-在别处被登录' |
反例
1 | `session_status` varchar(2) COLLATE utf8_bin NOT NULL COMMENT 'session授权态' |
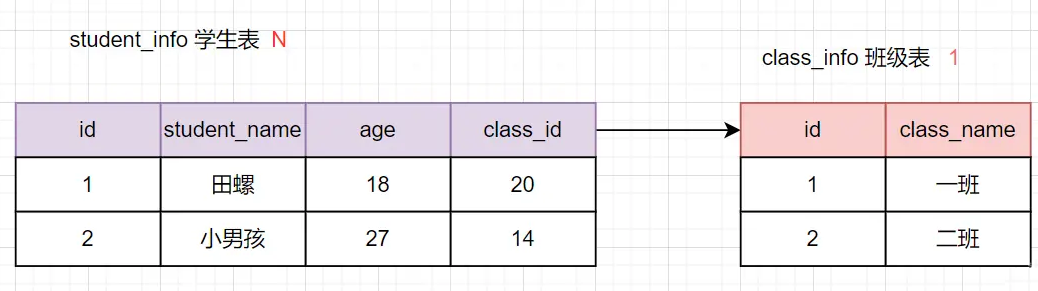
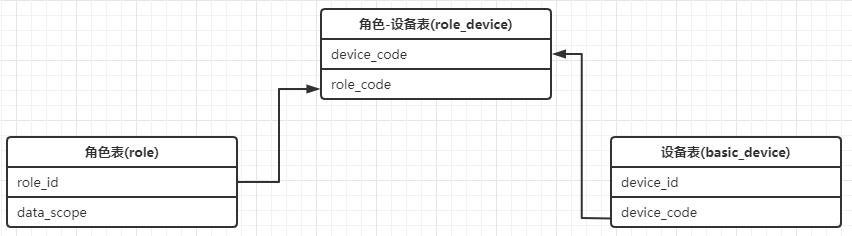
8. (1 : N) 、(N : N)关系的设计
1 : N 表的设计
从表(N的这一方)创建一个字段,以字段作为外键指向主表(1的这一方)的主键
N : N表设计
通过增加第三张表,把N:N修改为两个 1:N,例如 RBAC 表的设计
9. 不搞外键关联,一般都在代码维护
什么是外键呢?
- 外键,也叫FOREIGN KEY,它是用于将两个表连接在一起的键。
- FOREIGN KEY是一个表中的一个字段(或字段集合),它引用另一个表中的PRIMARY KEY。它是用来保证数据的一致性和完整性的。
阿里的Java规范也有这么一条:
- 【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
我们为什么不推荐使用外键呢?
- 使用外键存在性能问题、并发死锁问题、使用起来不方便等等。
- 每次做DELETE或者UPDATE都必须考虑外键约束,会导致开发的时候很难受,测试数据造数据也不方便。
- 还有一个场景不能使用外键,就是分库分表。
10. 参考博文
 wechat
wechat alipay
alipay