1. 内容大纲
本章节代码:https://github.com/wicksonZhang/data-structure/tree/main/14-Trie
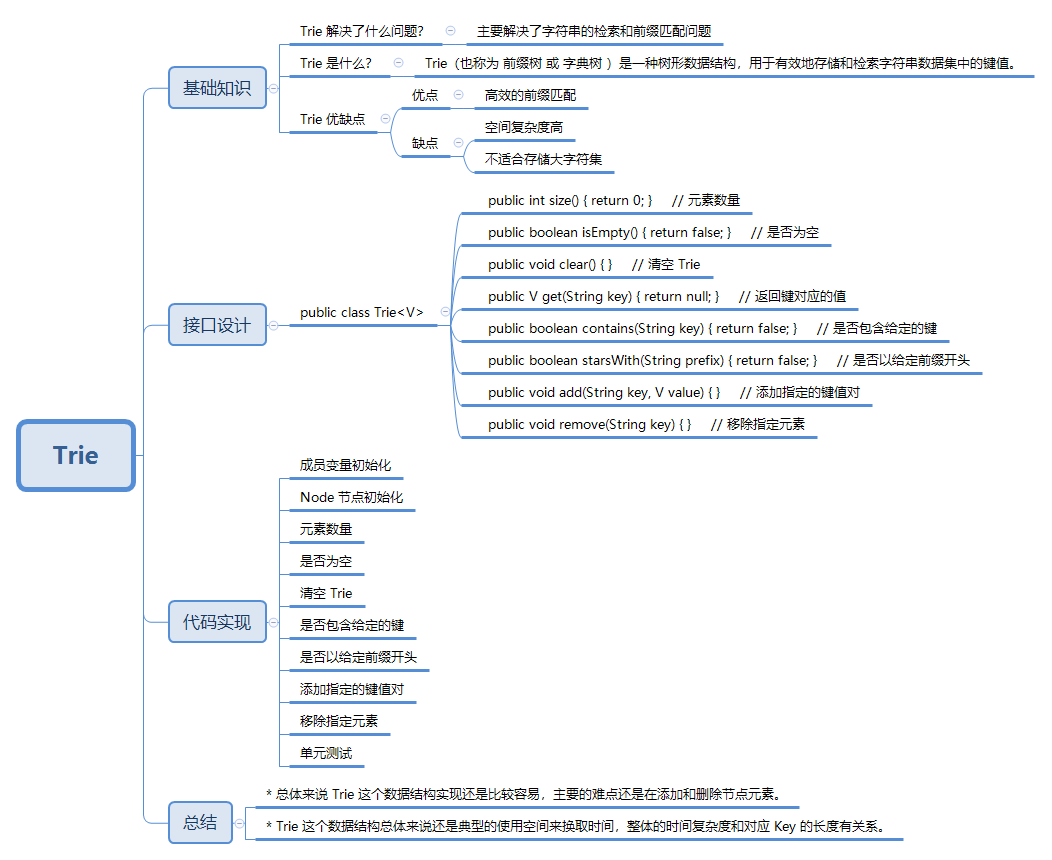
2. 基础知识
2.1. Trie 解决了什么问题?
Trie:主要解决了字符串的检索和前缀匹配问题,可以在 O(m) 的时间复杂度内检索具有特定前缀的字符串集合,其中 m 是要搜索的字符串的长度。
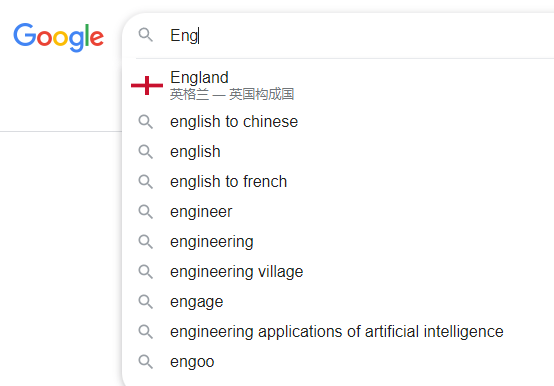
例如,我们可以借助 Trie 数据结构来实现自动补全、拼写检查等等。如下我们在 Google 浏览器中输入 eng 下面则会出现对应的单词进行补全。
2.2. Trie 是什么?
Trie(也称为 前缀树 或 字典树 )是一种树形数据结构,用于有效地存储和检索字符串数据集中的键值。
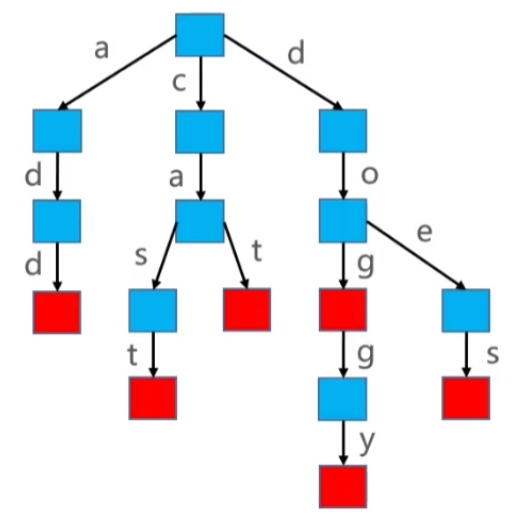
例如,我们需要存储 cat、dog、doggy、does、cast、add 这六个单词,使用 Tire 存储的数据格式如下:
2.3. Trie 优缺点
优点
- 高效的前缀匹配:Trie 具有高效的前缀匹配能力,可以在 O(m) 的时间复杂度内检索具有特定前缀的字符串集合,其中 m 是要搜索的字符串的长度。
缺点
- 空间复杂度高:Trie 数据结构会大量的占用内存,造成空间的浪费。
- 不适合存储大字符集:当字符集很大时,比如 Unicode 字符集,Trie 的存储和遍历操作可能会变得复杂和低效。
3. 接口设计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| public class Trie<V> {
public int size() { return 0; }
public boolean isEmpty() { return false; }
public void clear() { }
public V get(String key) { return null; }
public boolean contains(String key) { return false; }
public boolean starsWith(String prefix) { return false; }
public void add(String key, V value) { }
public void remove(String key) { }
}
|
4. 代码实现
4.1. 成员变量初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public class Trie<V> {
private int size;
private Node<V> root;
}
|
4.2. Node 节点初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
private static class Node<V> {
Node<V> parentNode;
HashMap<Character, Node<V>> childNode;
Character character;
V value;
boolean isEndOfWord;
public Node(Node<V> parentNode) {
this.parentNode = parentNode;
}
}
|
4.3. 元素数量
1
2
3
4
5
6
7
8
|
public int size() {
return size;
}
|
4.4. 是否为空
1
2
3
4
5
6
7
8
|
public boolean isEmpty() {
return size == 0;
}
|
4.5. 清空 Trie
1
2
3
4
5
6
7
|
public void clear() {
size = 0;
root = null;
}
|
4.6. 是否包含给定的键
1
2
3
4
5
6
7
8
9
10
|
public boolean contains(String key) {
Node<V> node = node(key);
return node != null && node.isEndOfWord;
}
|
4.7. 是否以给定前缀开头
1
2
3
4
5
6
7
8
9
|
public boolean startsWith(String prefix) {
return node(prefix) != null;
}
|
4.8. 添加指定的键值对
我们添加 cat、dog、doggy、does、cast、add 这六个单词,具体示例图如下:
实现思路
- Step-1:如果是第一次添加,则需要将根节点进行初始化;
- Step-2:遍历具体的 key ,并创建对应节点,将节点元素添加到根结点中;
- Step-3:如果 Key 已经存在,如果存在则将旧值进行返回;
- Step-4:如果 Key 不存在,则对节点重新赋值;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
public void add(String key, V value) {
checkKey(key);
if (root == null) {
root = new Node<>(null);
}
Node<V> node = root;
for (int i = 0; i < key.length(); i++) {
char ch = key.charAt(i);
Node<V> childNode = node.childNode == null ? null : node.childNode.get(ch);
if (childNode == null) {
childNode = new Node<>(node);
childNode.character = ch;
node.childNode = node.childNode == null ? new HashMap<>() : node.childNode;
node.childNode.put(ch, childNode);
}
node = childNode;
}
if (node.isEndOfWord) {
node.value = value;
return;
}
node.value = value;
node.isEndOfWord = true;
size++;
}
|
4.9. 移除指定元素
移除指定元素,我们分为如下几种情况:
找不到对应的 Key 或者 对应的 key 不是单词的结尾
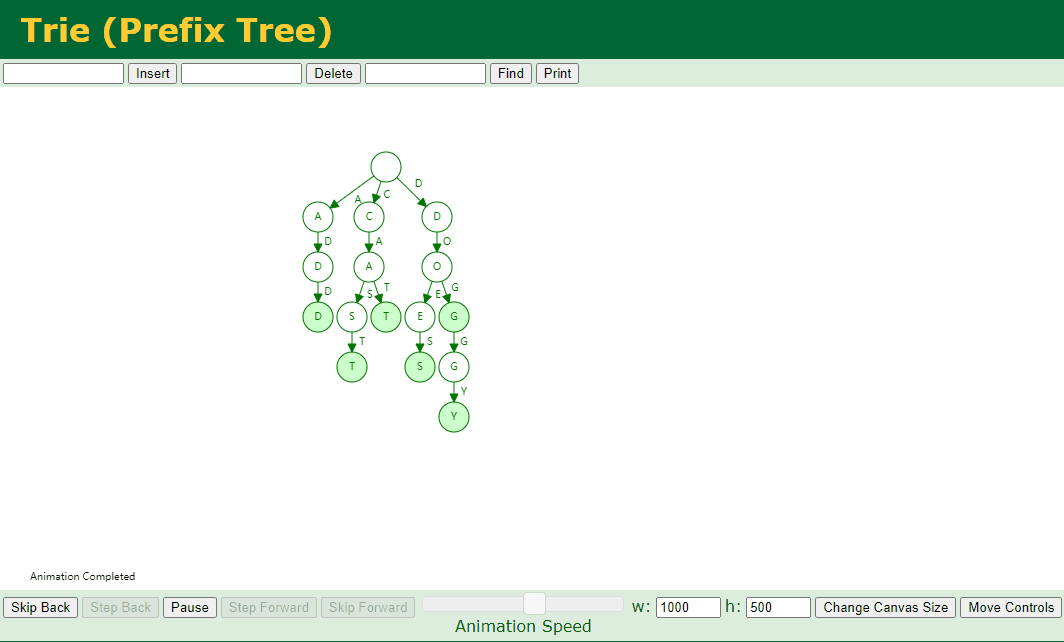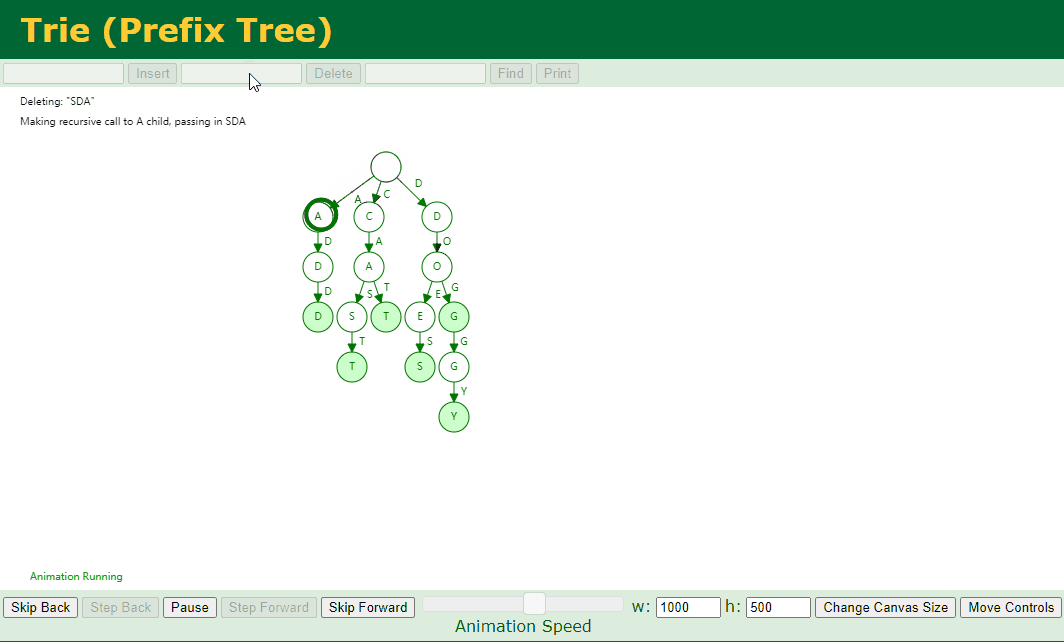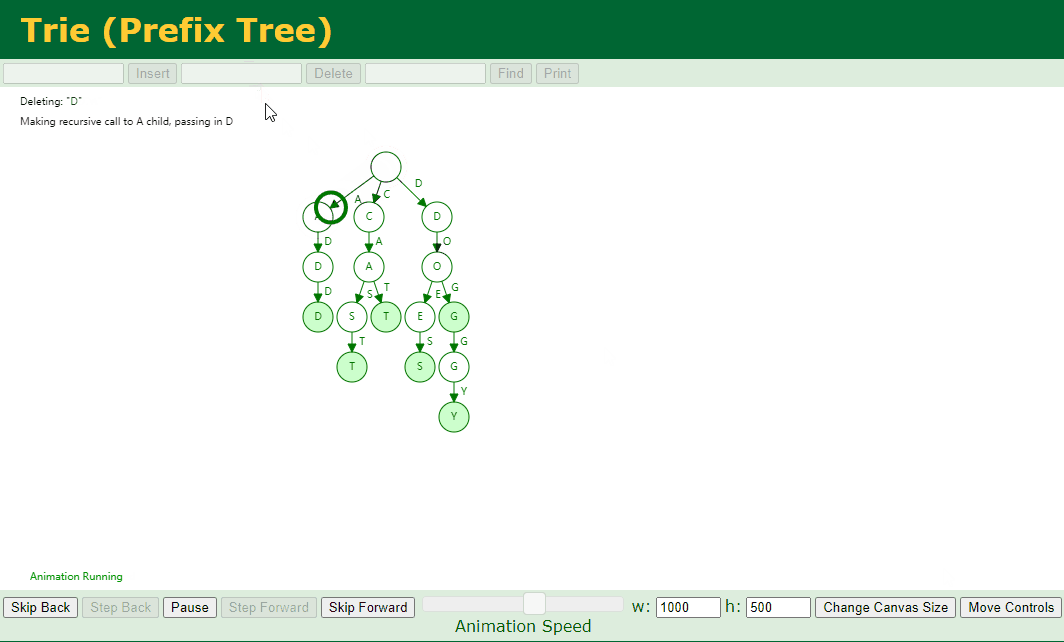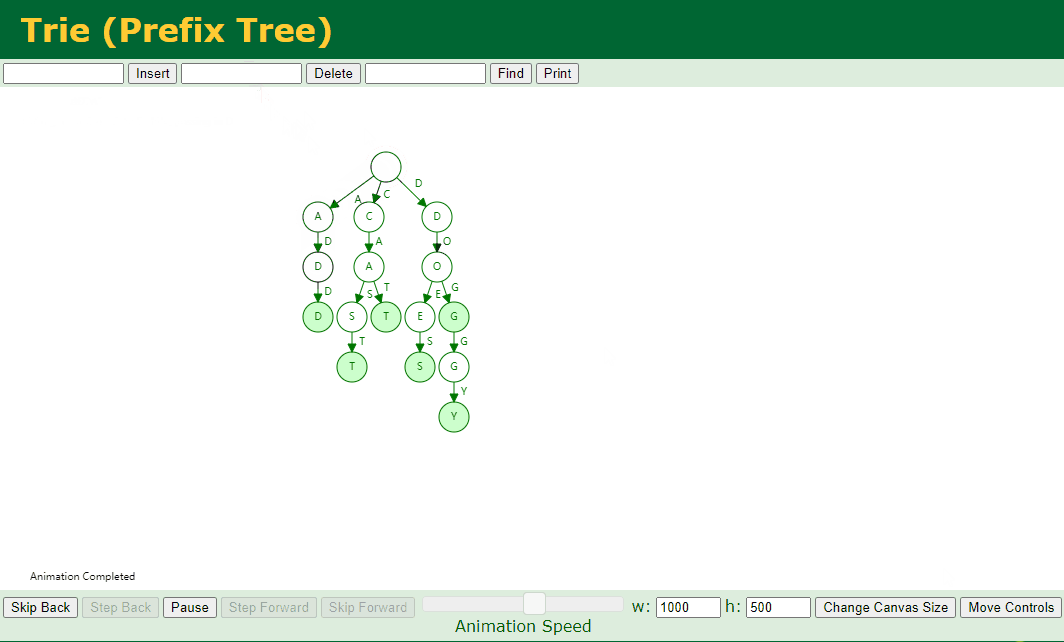
对应的 Key 存在子节点,例如我们删除 dog
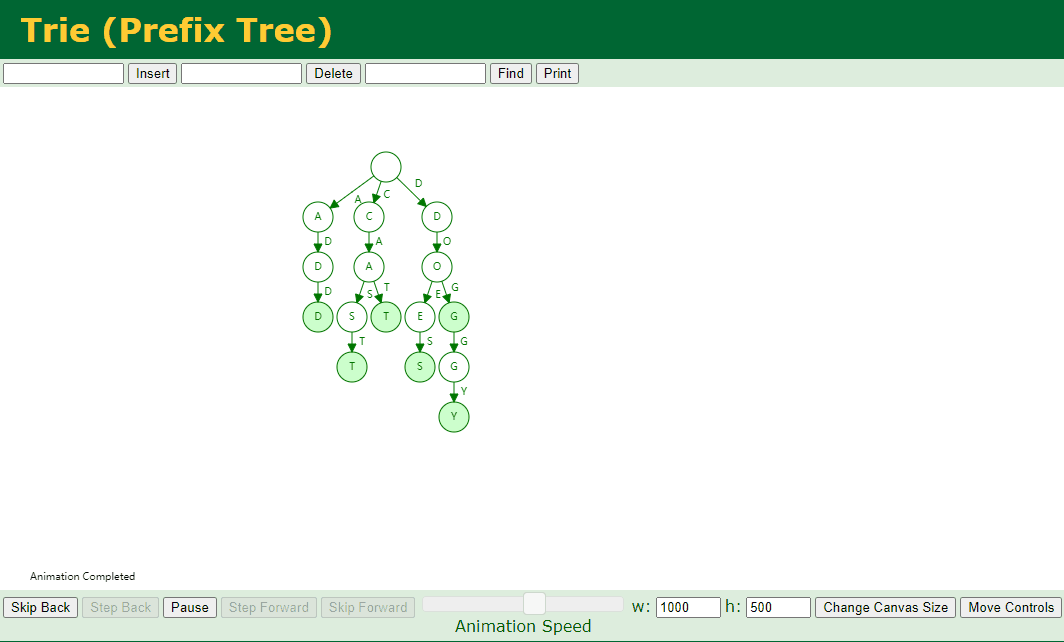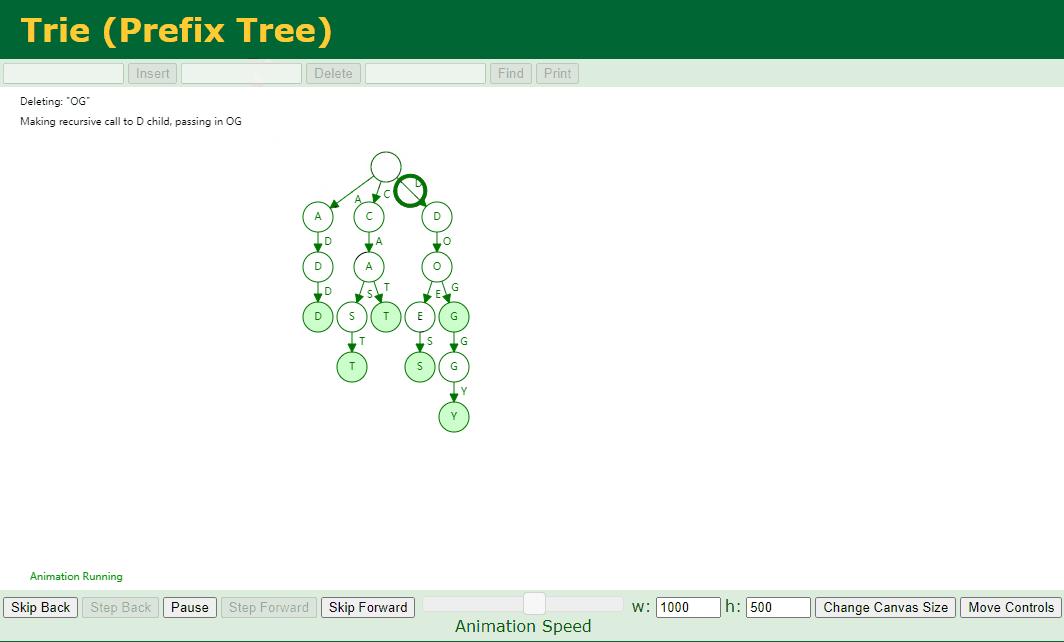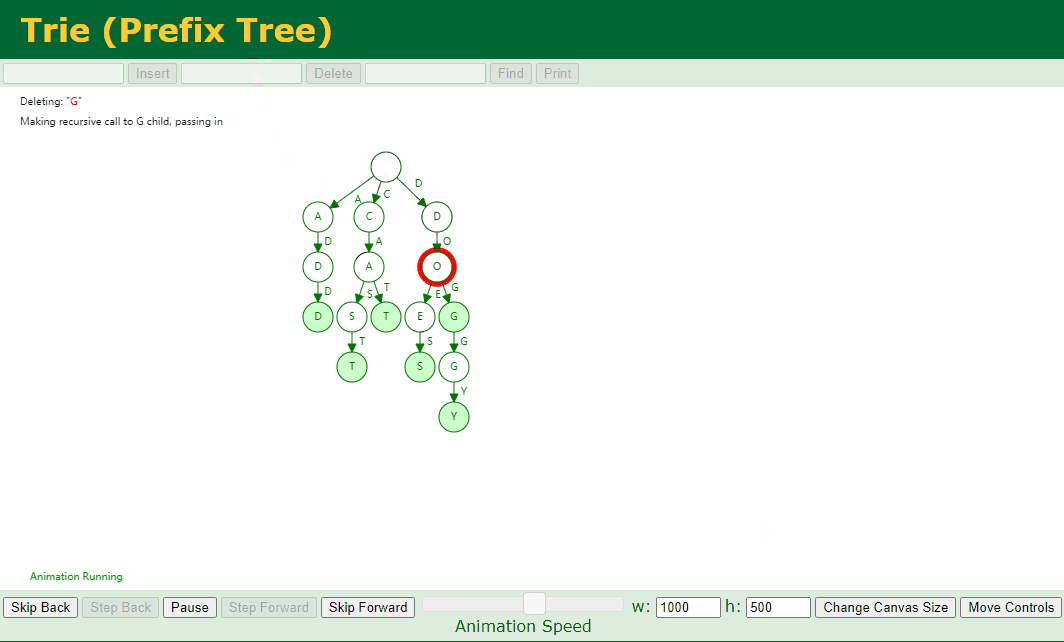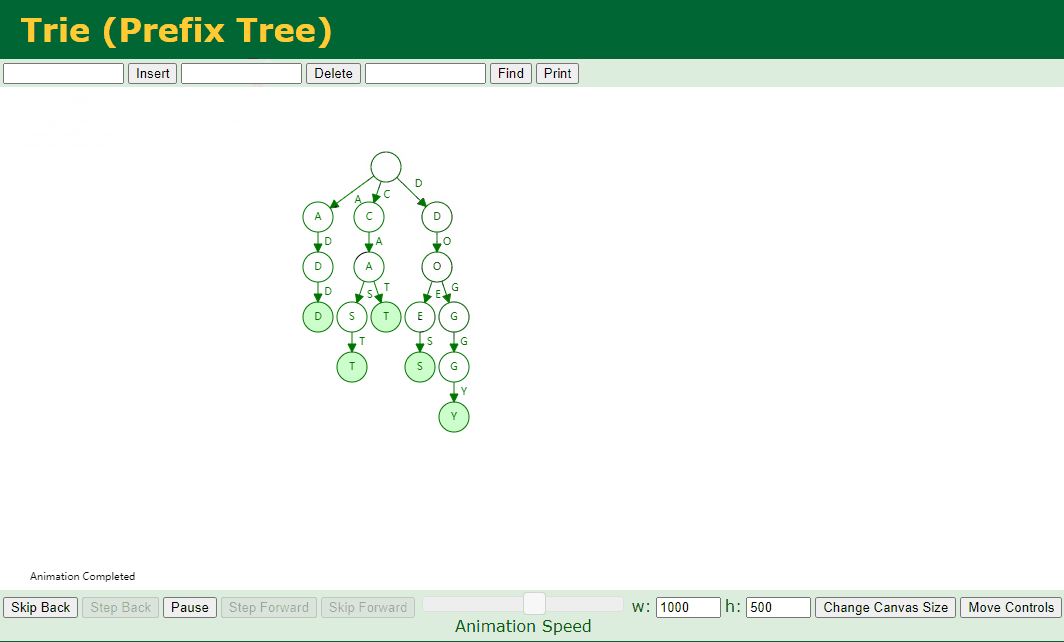
对应的 Key 不存在子节点 并且 对应的 Key 中存在好几个 Key,例如我们删除 add、doggy
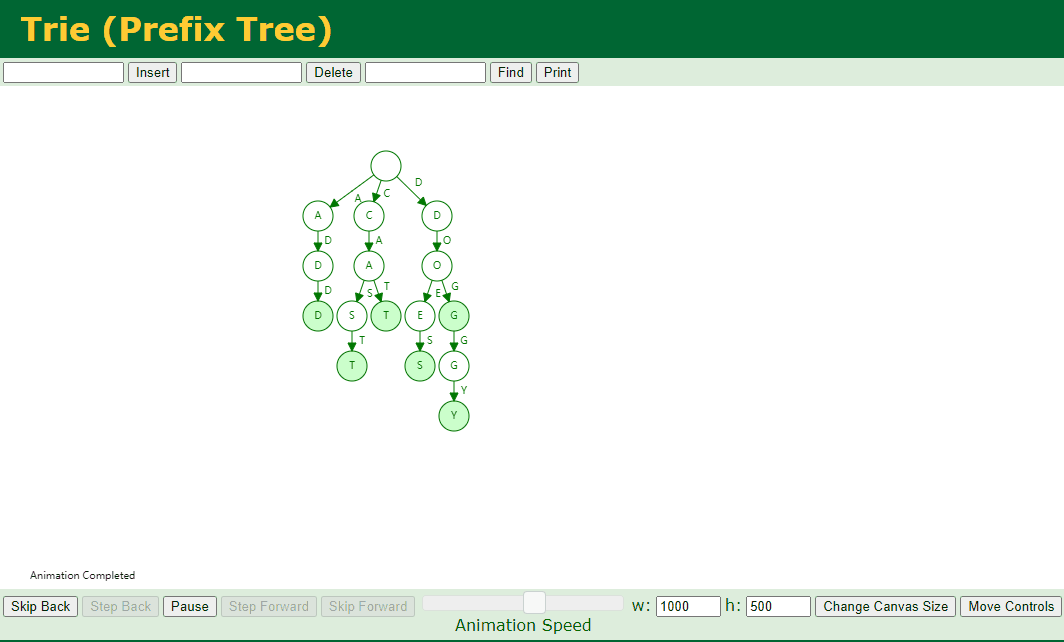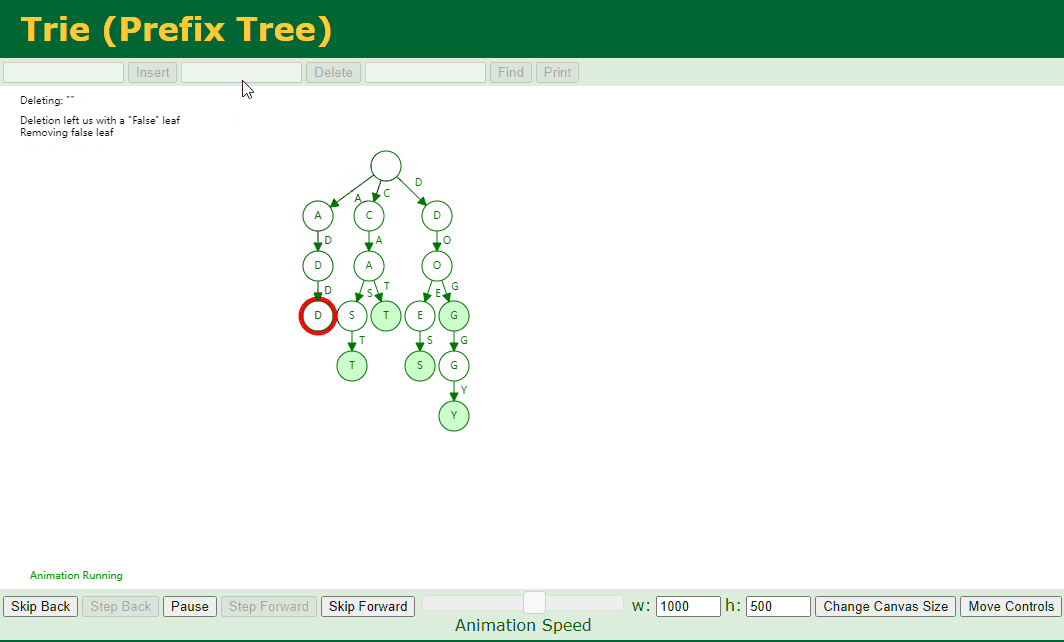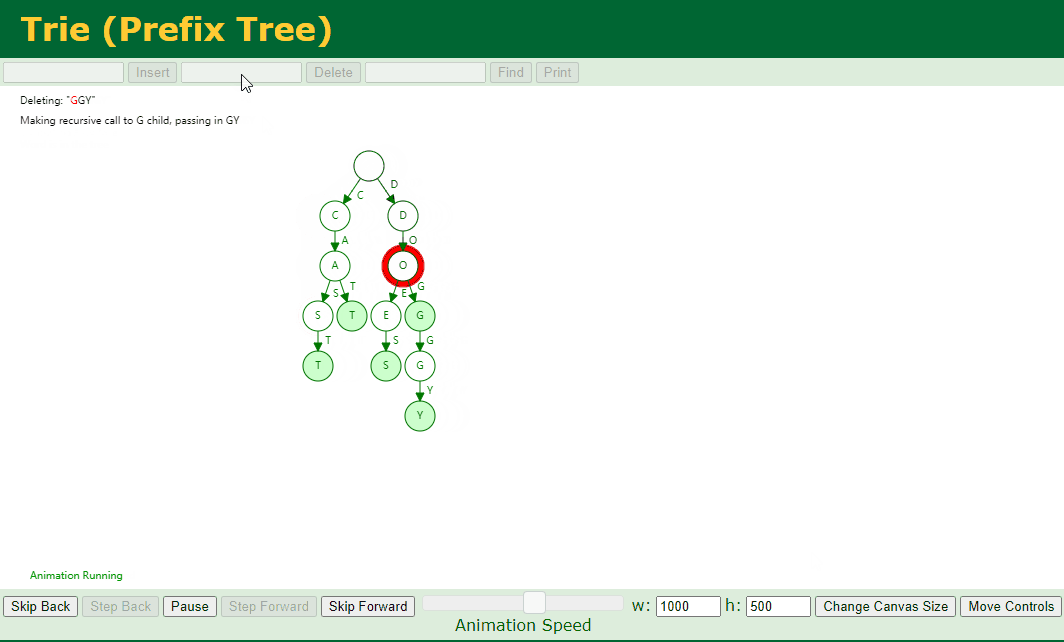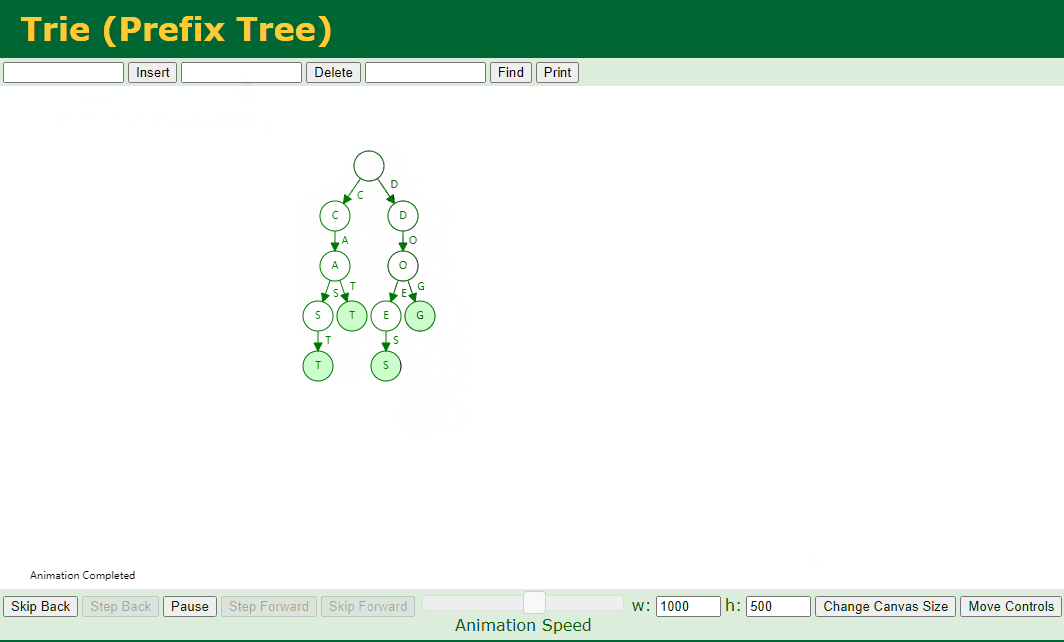
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
public V remove(String key) {
Node<V> node = node(key);
if (node == null || !node.isEndOfWord) {
return null;
}
V oldValue = node.value;
if (node.childNode != null && !node.childNode.isEmpty()) {
node.isEndOfWord = false;
node.value = null;
return oldValue;
}
Node<V> parentNode;
while ((parentNode = node.parentNode) != null) {
parentNode.childNode.remove(node.character);
if (parentNode.isEndOfWord || !parentNode.childNode.isEmpty()) {
break;
}
node = parentNode;
}
size--;
return oldValue;
}
|
4.10. 单元测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| public class TrieTest {
@Test
public void testAddAndGet() {
Trie<Integer> trie = new Trie<>();
trie.add("apple", 5);
trie.add("banana", 10);
Assertions.assertEquals(5, trie.get("apple"));
Assertions.assertEquals(10, trie.get("banana"));
Assertions.assertNull(trie.get("orange"));
}
@Test
public void testContains() {
Trie<Integer> trie = new Trie<>();
trie.add("apple", 5);
trie.add("banana", 10);
Assertions.assertTrue(trie.contains("apple"));
Assertions.assertTrue(trie.contains("banana"));
Assertions.assertFalse(trie.contains("orange"));
}
@Test
public void testRemove() {
Trie<Integer> trie = new Trie<>();
trie.add("apple", 5);
trie.add("banana", 10);
Assertions.assertEquals(5, trie.remove("apple"));
Assertions.assertFalse(trie.contains("apple"));
Assertions.assertNull(trie.get("apple"));
Assertions.assertEquals(10, trie.get("banana"));
}
@Test
public void testSizeAndClear() {
Trie<Integer> trie = new Trie<>();
trie.add("apple", 5);
trie.add("banana", 10);
Assertions.assertEquals(2, trie.size());
Assertions.assertFalse(trie.isEmpty());
trie.clear();
Assertions.assertEquals(0, trie.size());
Assertions.assertTrue(trie.isEmpty());
Assertions.assertNull(trie.get("apple"));
Assertions.assertNull(trie.get("banana"));
}
@Test
public void testStartsWith() {
Trie<Integer> trie = new Trie<>();
trie.add("apple", 5);
trie.add("banana", 10);
Assertions.assertTrue(trie.startsWith("app"));
Assertions.assertTrue(trie.startsWith("ban"));
Assertions.assertFalse(trie.startsWith("ora"));
}
}
|
5. 总结
- 总体来说 Trie 这个数据结构实现还是比较容易,主要的难点还是在添加和删除节点元素。
- Trie 这个数据结构总体来说还是典型的使用空间来换取时间,整体的时间复杂度和对应 Key 的长度有关系。
6. 参考博文
 wechat
wechat alipay
alipay



