1. 内容大纲
本章节代码:https://github.com/wicksonZhang/data-structure/tree/main/11-Hash
2. 基础知识
2.1. 哈希表解决了什么问题?
哈希表主要解决了在大规模数据集中快速查找元素的问题,哈希表通过映射可以将查询的时间复杂度维持在 O(1) 级别。
假设我们有一个存储学生信息的系统,每个学生都有一个唯一的学生ID。我们希望能够快速地通过学生ID检索到对应的学生信息,而不需要遍历整个数据集来查找。哈希表通过一个哈希函数将每个学生ID映射到数组的特定位置,这个位置就是该学生信息在数组中的存储位置。这样,我们就可以通过学生ID快速地定位到对应的数组位置,而不需要遍历整个数组。
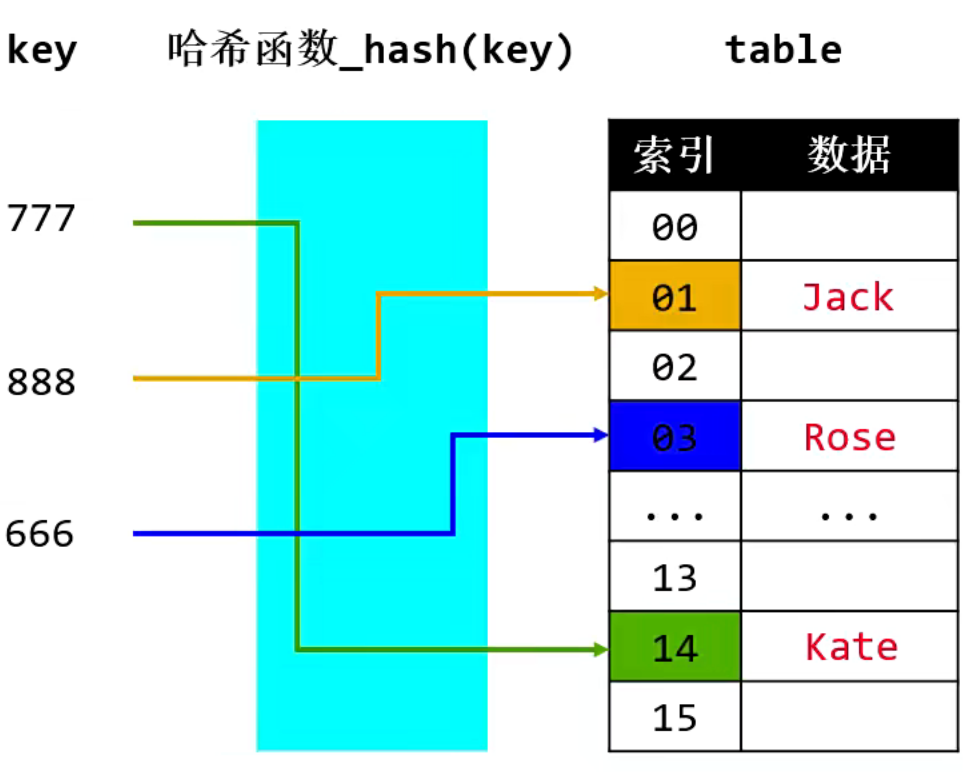
2.2. 哈希表是什么?
哈希表(Hash Table)是一种数据结构,用于实现键值对之间的映射关系。它通过将键(key)通过哈希函数映射到一个特定的索引位置,然后在该位置存储相应的值(value)。这使得在搜索、插入和删除操作中能够快速地定位和访问数据,这也使得了哈希表是以空间来换取时间。
哈希表的关键特点如下:
- 哈希函数:将键映射到索引的函数。良好设计的哈希函数能够最小化碰撞(collision)的概率,即不同的键映射到相同的索引位置的情况。
- 碰撞处理: 当两个不同的键映射到相同的索引位置时,需要一种方法来处理碰撞。常见的方法有链地址法和开放寻址法。
- 数组(桶): 存储实际数据的位置。每个索引位置通常称为一个桶,可能存储一个或多个键值对,以处理碰撞。
2.3. 哈希表优缺点
优点
- 快速的查找、插入和删除操作: 在平均情况下,哈希表的这些操作的时间复杂度为 O(1),即常数时间。
- 灵活的数据存储: 可以存储任意类型的数据作为值,而键可以是几乎任何数据类型。
缺点
- 碰撞可能导致性能下降: 如果两个不同的键映射到相同的索引位置,就会发生碰撞。
- 空间复杂度可能较高: 在某些情况下,为了避免碰撞,可能需要分配更多的空间,导致空间复杂度相对较高。
- 不适用于有序数据: 哈希表不保持键值对的顺序,因此对于需要有序访问的情况,可能不是最佳选择。
3. 哈希函数
如下是 hash 函数的计算公式
- 计算方式一:
hashCode(key) % table.length;
1
2
3
| public int hash(Object key) {
return hashCode(key) % table.length;
}
|
- 计算方式二(推荐方式):
hashCode(key) & (table.length - 1);
- 注意:数组的长度设计为 2 的幂(2^n)
1
2
3
| public int hash(Object key) {
return hashCode(key) & (table.length - 1);
}
|
| 方式 |
哈希值 |
计算方式 |
数组长度 |
索引值 |
| 计算方式一 |
十进制:202 |
% |
十进制:16 |
十进制:10 |
| 计算方式二 |
二进制:11001010 |
& |
二进制:1111 |
二进制:1010 |
- 总结:良好的哈希值能够最小化碰撞(collision)的概率,减少哈希碰撞的次数,提升哈希性能。
4. 哈希值的计算
注意: 哈希值一定是一个整数,最后的索引值才会是整数。
哈希值的类型可以分为很多种,例如 整数类型、浮点类型、字符串类型 等等。根据不同的类型会产生不同的哈希值,在下面会分别进行讨论:
4.1. 整数类型(int、long)
int 类型
- 整数类型 int 的哈希值就是整型,具体代码如下:
1
2
3
| public int hashCode(int key) {
return key;
}
|
long 类型
- long 是长整型占 8 个字节 64 位,但是最后返回的哈希值是 int 整型,所以需要将 64 位长整型的值进行一些位运算操作,并将结果截断为32位整型。
value >>> 32: 这是一个无符号右移操作符,它将value的二进制表示向右移动32位。value ^ (value >>> 32): 这是一个按位异或操作符(^),它对两个二进制数进行位级别的异或运算。(int)(value ^ (value >>> 32)): 最后,将得到的64位值强制类型转换为32位整型。这将导致只保留结果的低32位,丢弃高32位。
1
2
3
| public int hashCode(long key) {
return (int) (key ^ (key >>> 32));
}
|
4.2. 浮点类型(float、double)
float 类型
- 浮点类型 float 的不是整型,我们可以得到 float 的二进制数,再将二进制转为对应的十进制,具体代码如下:
1
2
3
| public int hashCode(float key) {
return Float.floatToIntBits(key);
}
|
1
2
3
4
5
6
7
| @Test
public void hashCodeByFloat() {
float key = 7.2f;
int code = Float.floatToIntBits(key);
System.out.println("code = " + code);
System.out.println("code = " + Integer.toBinaryString(code));
}
|
double 类型
- long 是长整型占 8 个字节 64 位,我们可以将 double 转为 long 类型,然后进行位运算,并将结果截断为32位整型。
Double.doubleToLongBits(key): 这个方法将一个双精度浮点数 key 转换为一个长整型 long 的比特表示。code ^ (code >>> 32): 这是一个按位异或操作符(^),它将刚刚得到的64位长整型 code 与右移32位后的值进行异或运算。(int) (code ^ (code >>> 32)): 最后,将得到的64位值强制类型转换为32位整型。
1
2
3
4
| public int hashCode(float key) {
long code = Double.doubleToLongBits(key);
return (int) (code ^ (code >>> 32));
}
|
4.3. 字符串类型(String)
字符串的类型和二进制转十进制的方式有点类似,具体代码如下:
1
2
3
4
5
6
7
| public int hashCode(String key) {
int hashCode = 0;
for (int i = 0; i < key.length(); i++) {
hashCode = hashCode * 31 + key.charAt(i);
}
return hashCode;
}
|
如下是字符串类型的证明过程,字符串的类型和二进制转十进制的方式有点类似。
- 例如字符串
Jack,本质上还是由字符组成(字符的本质就是一个 ASCII 数),所以哈希值可以表示为 J * n^3 + a * n^2 + c * n^1 + k * n^0
- 我们将
J * n^3 + a * n^2 + c * n^1 + k * n^0 简化为 [(j * n + a) * n + c] * n + k,在 JDK 中可以将 n 看出 31
1
2
3
4
5
6
7
8
9
| @Test
public void hashCodeByString() {
String key = "Jack";
int hashCode = 0;
for (int i = 0; i < key.length(); i++) {
hashCode = hashCode * 31 + key.charAt(i);
}
System.out.println("hashCode = " + hashCode);
}
|
4.4. 自定义对象类型
对象类型的哈希值计算本质上还是对字段的属性进行计算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public class Person {
private int age;
private float height;
private String name;
public Person(int age, float height, String name) {
this.age = age;
this.height = height;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Float.compare(person.height, height) == 0 && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
int hashCode = Integer.hashCode(age);
hashCode = hashCode + Float.hashCode(height);
hashCode = hashCode + name.hashCode();
return hashCode;
}
}
|
4.5. hashCode() 和 equals()
我们通过如下面 Person 案例来说明,为什么当对象重写了 hashCode() 之后一定要重写 equals()?
1
2
3
4
5
6
7
8
9
10
11
| @Test
public void hashCodeByObject() {
Person person = new Person(18, 175.1f, "jack");
Person person1 = new Person(18, 175.1f, "jack");
Map<Object, Object> hashMap = new HashMap<>();
hashMap.put(person, person);
hashMap.put(person1, person1);
hashMap.put("object", new Object());
System.out.println("hashMap.size() = " + hashMap.size());
}
|
问题一:如果不重写 Person 对象的 hashCode() 和 equals() 会怎样?
- 最后
hashMap.size() 打印的结果为 3
- 因为我们将对象作为 key ,而 key 存储的是内存地址,所以得出了 3.
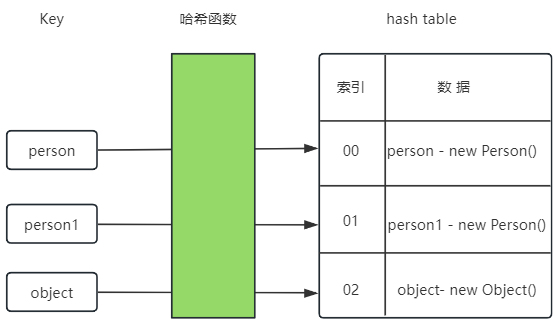
测试代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Test
public void hashCodeByObject() {
Person person = new Person(18, 175.1f, "jack");
Person person1 = new Person(18, 175.1f, "jack");
Map<Object, Object> hashMap = new HashMap<>();
hashMap.put(person, person);
hashMap.put(person1, person1);
hashMap.put("object", new Object());
hashMap.forEach((key, value) -> System.out.println("key = " + key + ", value = " +value));
System.out.println("hashMap.size() = " + hashMap.size());
}
|
问题二:如果重写 Person 对象的 hashCode() 和 equals() 会怎样?
- 最后
hashMap.size() 打印的结果为 2,因为 person1 Key 会把 person 的 Key 覆盖掉。
- 首先,调用
person 和 person1 的 key 通过 hashCode() 计算出来的值一定是一致的。
- 然后,在调用
person 和 person1 的 equals() 进行比较两个 key 是否一致,最后认定是同一个key。
- 最后,如果认定为同一个
key ,所以最后再将 person1 的 value 覆盖掉 person 的 value。
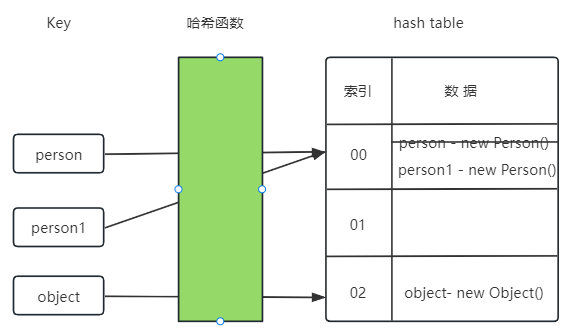
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @Test
public void hashCodeByObject() {
Person person = new Person(18, 175.1f, "jack");
Person person1 = new Person(18, 175.1f, "jack");
Map<Object, Object> hashMap = new HashMap<>();
hashMap.put(person, person);
hashMap.put(person1, person1);
hashMap.put("object", new Object());
hashMap.forEach((key, value) -> System.out.println("key = " + key + ", value = " +value));
System.out.println("hashMap.size() = " + hashMap.size());
}
|
问题三:如果重写 Person 对象的 hashCode() ,不重写 equals() 会怎样?
- 最后
hashMap.size() 打印的结果是 2。
- 首先,调用
person 和 person1 的 key 通过 hashCode() 计算出来的值一定是一致的。
- 然后,由于
person 和 person1 并未重写 equals() 方法,所以比较的是内存地址.
- 最后,通过链表的形式将
person1 追加到 person 后面,所有最后的 hashMap.size() 是 3.
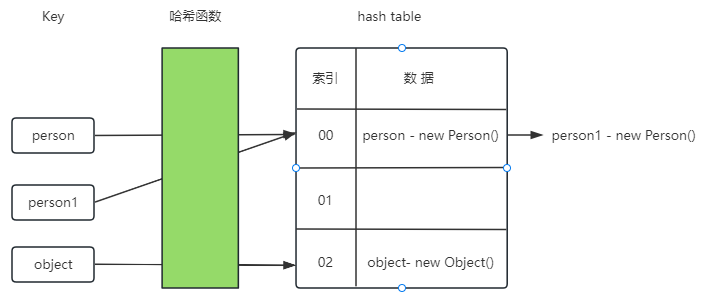
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @Test
public void hashCodeByObject() {
Person person = new Person(18, 175.1f, "jack");
Person person1 = new Person(18, 175.1f, "jack");
Map<Object, Object> hashMap = new HashMap<>();
hashMap.put(person, person);
hashMap.put(person1, person1);
hashMap.put("object", new Object());
hashMap.forEach((key, value) -> System.out.println("key = " + key + ", value = " +value));
System.out.println("hashMap.size() = " + hashMap.size());
}
|
问题四:如果重写 Person 对象的 equals() ,不重写 hashCode() 会怎样?
最后 hashMap.size() 打印的结果有可能是 2 或者 3。
当 hashMap.size() 结果为 3 时,具体分析情况如下:
- 由于没有重写
hashCode() ,通过 hashCode() 计算出来的索引值是不一致的,属于正常情况,情况如下:
当 hashMap.size() 结果为 2 时,具体分析情况如下:
- 首先,由于没有重写
hashCode() ,所以采用内存地址作为 key 。
- 然后,当把
key 作为内存地址进行比较时,如果最后得出的索引值是一致的就会产生碰撞。
- 最后,碰撞之后就会比较
equlas() ,但最后结果是一致的就会将上一个 key 的 value 进行覆盖。
- 测试代码如下,我们创建了
100W 个对象,但最后的结果少了 233。
1
2
3
4
5
6
7
8
9
10
11
| @Test
public void hashCodeByObject() {
Map<Object, Object> hashMap = new HashMap<>();
for (int i = 0; i < 1000000; i++) {
Person person = new Person(18, 175.1f, "jack");
hashMap.put(person, person);
}
hashMap.forEach((key, value) -> System.out.println("key = " + key + ", value = " +value));
System.out.println("hashMap.size() = " + hashMap.size());
}
|
5. 哈希碰撞
哈希冲突也被称为哈希碰撞,指的是 2 个不同的 key 经过哈希函数计算出相同的结果。key1 ≠ key2,hash(key1) = hash(key2)
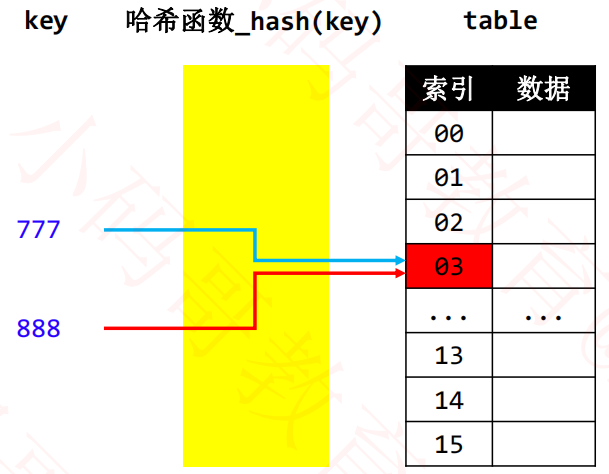
解决哈希碰撞的方法如下
- 开放寻址法:按照一定的规则向其他地址探测,一直到找到空桶。
- 在哈希法:设计多个哈希函数。
- 链地址发:通过链表将同一 index 的元素串起来。
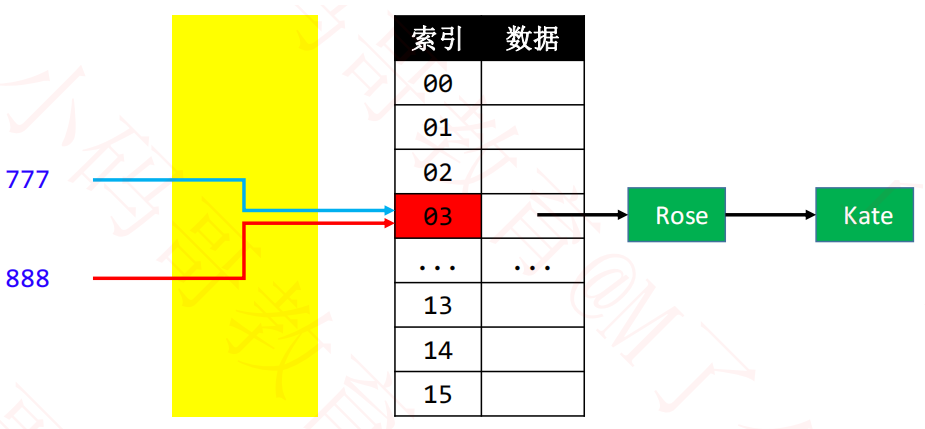
5.1. 链地址法
链地址法(Separate Chaining):通过链表将同一index的元素串起来。具体如下图
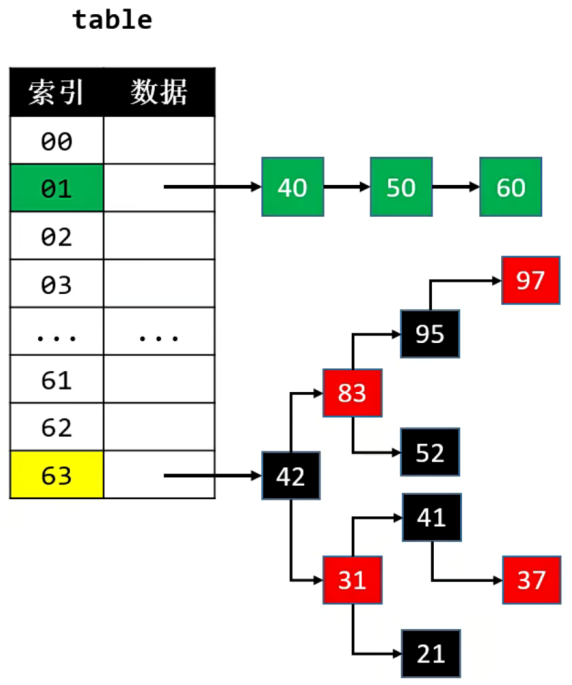
如下是 JDK 1.8 解决哈希冲突的方案
- 首先,添加元素是需要判断当前哈希表容量是否大于 64 且 单链表的节点数量是否大于 8。
- 然后,如果不满足上诉条件,哈希冲突时则采用单链表进行存储。如果满足上诉条件,则将链表转为红黑树。
- 最后,当红黑树节点数量少到一定程度时,又会转为单向链表。
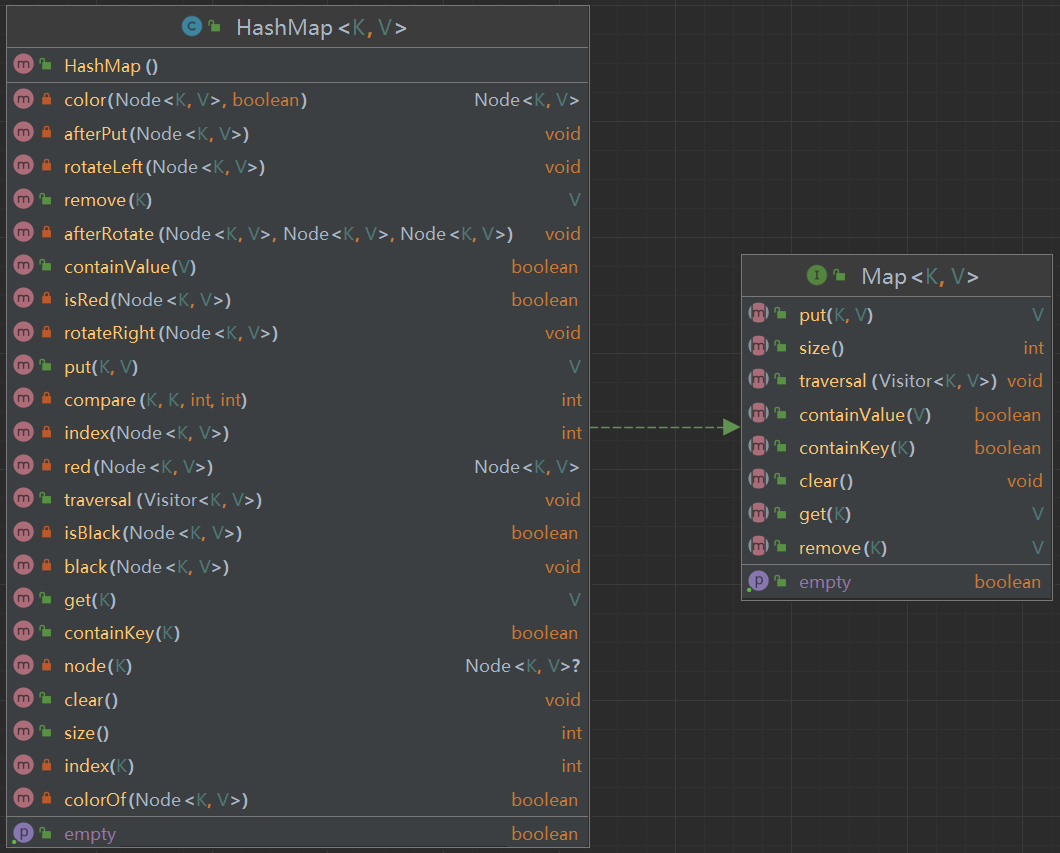
6. Map 接口设计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| public interface Map<K, V> {
int size();
boolean isEmpty();
void clear();
V put(K key, V value);
V get(K key);
V remove(K key);
boolean containKey(K key);
boolean containValue(V value);
void traversal(Visitor<K, V> visitor);
public static abstract class Visitor<K, V> {
public boolean stop;
public abstract boolean visit(K key, V value);
}
}
|
7. HashMap 具体实现
7.1. Node节点初始化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
|
public class HashMap<K, V> implements Map<K, V> {
private int size;
private Node<K, V>[] table;
private static final int DEFAULT_CAPACITY = 1 << 4;
public HashMap() {
this.table = new Node[DEFAULT_CAPACITY];
}
private static final boolean RED = false;
private static final boolean BLACK = true;
private static class Node<K, V> {
int hash;
K key;
V value;
boolean color = RED;
Node<K, V> leftNode;
Node<K, V> rightNode;
Node<K, V> parentNode;
public Node(K key, V value, Node<K, V> parentNode) {
this.key = key;
this.hash = key == null ? 0 : key.hashCode();
this.value = value;
this.parentNode = parentNode;
}
public boolean isLeaf() {
return leftNode == null && rightNode == null;
}
public boolean hasTwoChildren() {
return leftNode != null && rightNode != null;
}
public boolean isLeftChild() {
return parentNode != null && this == parentNode.leftNode;
}
public boolean isRightChild() {
return parentNode != null && this == parentNode.rightNode;
}
public Node<K, V> sibling() {
if (isLeftChild()) {
return parentNode.rightNode;
}
if (isRightChild()) {
return parentNode.leftNode;
}
return null;
}
}
}
|
7.2. 元素数量
1
2
3
4
5
6
7
8
9
|
@Override
public int size() {
return size;
}
|
7.3. 是否为空
1
2
3
4
5
6
7
8
9
|
@Override
public boolean isEmpty() {
return size == 0;
}
|
7.4. 清除所有元素
1
2
3
4
5
6
7
8
9
10
11
|
@Override
public void clear() {
if (size == 0) return;
for (int i = 0; i < table.length; i++) {
table[i] = null;
}
size = 0;
}
|
7.5. 添加元素
7.6. 获取元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| @Override
public V get(K key) {
Node<K, V> node = node(key);
return node != null ? node.value : null;
}
private Node<K,V> node(K key) {
Node<K, V> node = table[index(key)];
int h1 = key == null ? 0 : key.hashCode();
while (node != null) {
int compare = compare(key, node.key, h1, node.hash);
if (compare == 0) {
return node;
}
if (compare > 0) {
node = node.rightNode;
} else {
node = node.leftNode;
}
}
return null;
}
|
7.7. 删除元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| @Override
public V remove(K key) {
return remove(node(key));
}
private V remove(Node<K, V> node) {
if (node == null) {
return null;
}
V oldValue = node.value;
if (node.hasTwoChildren()) {
Node<K, V> predecessorNode = successor(node);
node.key = predecessorNode.key;
node.value = predecessorNode.value;
node = predecessorNode;
}
Node<K, V> removeNode = node.leftNode != null ? node.leftNode : node.rightNode;
int index = index(node);
if (removeNode != null) {
removeNode.parentNode = node.parentNode;
if (removeNode.parentNode == null) {
table[index] = removeNode;
} else if (node == node.parentNode.leftNode) {
node.parentNode.leftNode = removeNode;
} else {
node.parentNode.rightNode = removeNode;
}
afterRemove(removeNode);
} else if (node.parentNode == null) {
table[index] = null;
afterRemove(node);
} else {
if (node == node.parentNode.leftNode) {
node.parentNode.leftNode = null;
} else {
node.parentNode.rightNode = null;
}
afterRemove(node);
}
size--;
return oldValue;
}
|
7.8. 是否包含 Value
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| @Override
public boolean containValue(V value) {
if (size == 0) {
return false;
}
Queue<Node<K, V>> queue = new LinkedList<>();
for (Node<K, V> kvNode : table) {
if (kvNode == null) {
continue;
}
queue.offer(kvNode);
while (!queue.isEmpty()) {
Node<K, V> node = queue.poll();
if (Objects.equals(value, node.value)) {
return true;
}
if (node.leftNode != null) {
queue.offer(node.leftNode);
}
if (node.rightNode != null) {
queue.offer(node.rightNode);
}
}
}
return false;
}
|
7.9. 是否包含 Key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @Override
public boolean containKey(K key) {
return node(key) != null;
}
private Node<K,V> node(K key) {
Node<K, V> node = table[index(key)];
int h1 = key == null ? 0 : key.hashCode();
while (node != null) {
int compare = compare(key, node.key, h1, node.hash);
if (compare == 0) {
return node;
}
if (compare > 0) {
node = node.rightNode;
} else {
node = node.leftNode;
}
}
return null;
}
|
7.10. 遍历集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @Override
public void traversal(Visitor<K, V> visitor) {
if (size == 0 || visitor == null) {
return;
}
Queue<Node<K, V>> queue = new LinkedList<>();
for (Node<K, V> kvNode : table) {
if (kvNode == null) {
continue;
}
queue.offer(kvNode);
while (!queue.isEmpty()) {
Node<K, V> node = queue.poll();
if (visitor.visit(node.key, node.value)) {
return;
}
if (node.leftNode != null) {
queue.offer(node.leftNode);
}
if (node.rightNode != null) {
queue.offer(node.rightNode);
}
}
}
}
|
8. 参考博文
 wechat
wechat alipay
alipay



